

Китайский производитель систем управления облачными сервисами для комплексного мони
Многие сейчас говорят о облачных решениях и автоматизации мониторинга, а зачастую – это просто модные слова. Как будто замена старых систем на 'облако' автоматически решает все проблемы. Но на деле, системы управления облачными сервисами для комплексного мониторинга – это комплексная задача, требующая понимания не только облачных технологий, но и специфики бизнеса и инфраструктуры. Особенно, если речь идет о надежности и безопасности данных.
Что такое комплексное управление мониторингом в облаке?
Давайте сразу определимся, что мы подразумеваем под 'комплексным'. Это не просто сбор метрик CPU и памяти. Это – интеграция мониторинга всех уровней: инфраструктуры (серверы, сети, диски), приложений, контейнеров, микросервисов, а также даже бизнес-показателей. Цель – получить единую картину состояния всей системы и оперативно реагировать на возникающие инциденты. И, конечно, автоматизация реагирования – это тоже важная часть комплексного подхода. Мы не просто видим проблему, мы хотим, чтобы система сама пыталась ее решить, будь то перезапуск сервиса или масштабирование ресурсов.
И вот тут начинается самое интересное. Представление, что готовое решение 'из коробки' сможет решить все задачи, часто оказывается ошибочным. Например, у нас был случай с одним из клиентов – крупной логистической компанией. Они выбрали популярный облачный провайдер и стандартный набор инструментов для мониторинга. Но оказалось, что стандартные метрики не давали полного представления о производительности их критически важных приложений, обрабатывающих данные о доставке. Им требовалось отслеживать, например, время обработки транзакций, количество ошибок и задержки в работе API. Просто посмотреть на загрузку CPU недостаточно.
Вызовы интеграции и кастомизации
Интеграция различных инструментов и сервисов – это всегда головная боль. Особенно, когда речь идет о разнородной инфраструктуре, включающей как виртуальные машины, так и контейнеры (Docker, Kubernetes), а также разные языки программирования и базы данных. Мы сталкивались с ситуациями, когда необходимость получения данных из 'нестандартных' источников требовала разработки собственных интеграционных плагинов и скриптов. Это, конечно, требует определенных усилий и экспертизы, но без этого не обойтись.
Один из самых распространенных вызовов – это 'шум' в данных. Облачные среды генерируют огромное количество метрик, и важно уметь отфильтровывать то, что действительно важно, и не отвлекаться на незначительные отклонения. Для этого требуется настройка правил оповещений, мониторинг трендов и использование алгоритмов машинного обучения для выявления аномалий.
Архитектура системы: наш подход
В нашей практике мы обычно используем комбинацию различных инструментов: от open-source решений (Prometheus, Grafana, ELK stack) до коммерческих платформ (Datadog, New Relic). Выбор конкретного набора инструментов зависит от требований заказчика, бюджета и специфики инфраструктуры. Но, как правило, мы стараемся использовать модульную архитектуру, позволяющую гибко адаптироваться к изменяющимся потребностям.
Важным элементом системы является централизованное хранилище данных. Вместо того, чтобы хранить метрики в разных местах, мы собираем их в едином хранилище, что позволяет проводить анализ данных в реальном времени и создавать визуализации. Для этого мы часто используем Time Series Databases, такие как InfluxDB или TimescaleDB.
Пример реализации: мониторинг Kubernetes-кластера
Например, мы разработали решение для мониторинга Kubernetes-кластера, включающее сбор метрик с помощью Prometheus, визуализацию данных в Grafana и автоматическое оповещение об инцидентах в Slack. Также мы интегрировали систему с сервисом автоматического масштабирования, чтобы при превышении определенного порога ресурсов, автоматически увеличивать количество Pod'ов.
Особое внимание мы уделяем безопасности данных. Все данные передаются по зашифрованным каналам, и доступ к ним строго контролируется. Мы также регулярно проводим аудит системы на предмет уязвимостей.
Ошибки, которых стоит избегать
Мы видели немало ошибок при внедрении системы управления облачными сервисами для комплексного мониторинга. Вот некоторые из них:
- Недостаточное планирование: Прежде чем начинать внедрение, необходимо четко определить цели и задачи мониторинга, а также выбрать подходящие инструменты и архитектуру.
- Игнорирование автоматизации: Ручной мониторинг – это неэффективно и опасно. Необходимо максимально автоматизировать процесс мониторинга и реагирования на инциденты.
- Недостаток экспертизы: Внедрение сложных систем мониторинга требует специальных знаний и опыта. Не стоит пытаться сделать все самостоятельно, если у вас нет необходимых ресурсов.
- Неправильная настройка оповещений: Слишком много оповещений – это шум, который отвлекает от важных событий. Слишком мало оповещений – это риск пропустить критический инцидент.
- Отсутствие Continuous Integration/Continuous Deployment (CI/CD) для мониторинга: Мониторинг должен развиваться вместе с приложением, необходимо автоматизировать развертывание и тестирование мониторинговых компонентов.
Часто недостаточно внимания уделяется обучению персонала. Даже самая современная система мониторинга будет бесполезна, если никто не знает, как ее использовать.
Будущее мониторинга в облаке
Мы уверены, что системы управления облачными сервисами для комплексного мониторинга будут становиться все более сложными и интеллектуальными. В будущем мы увидим более широкое использование машинного обучения и искусственного интеллекта для автоматизации мониторинга и реагирования на инциденты. Также, наблюдается тренд на DevOps-мониторинг, когда мониторинг интегрируется в процесс разработки и развертывания программного обеспечения.
В заключение хочу сказать, что внедрение системы управления облачными сервисами для комплексного мониторинга – это не одноразовое мероприятие, а непрерывный процесс. Необходимо постоянно отслеживать новые технологии, анализировать данные и адаптировать систему к изменяющимся потребностям бизнеса. И, конечно, важно помнить, что самая лучшая система мониторинга – это та, которая действительно помогает решать проблемы и обеспечивать надежность и безопасность бизнеса.
Соответствующая продукция
Соответствующая продукция





Самые продаваемые продукты
Самые продаваемые продукты-
 Шкаф электропитания EPS для освещения серии RK-D
Шкаф электропитания EPS для освещения серии RK-D -
 Промышленные модульные ИБП серии HS9100 (3-фазный вход / 3-фазный или однофазный выход)
Промышленные модульные ИБП серии HS9100 (3-фазный вход / 3-фазный или однофазный выход) -
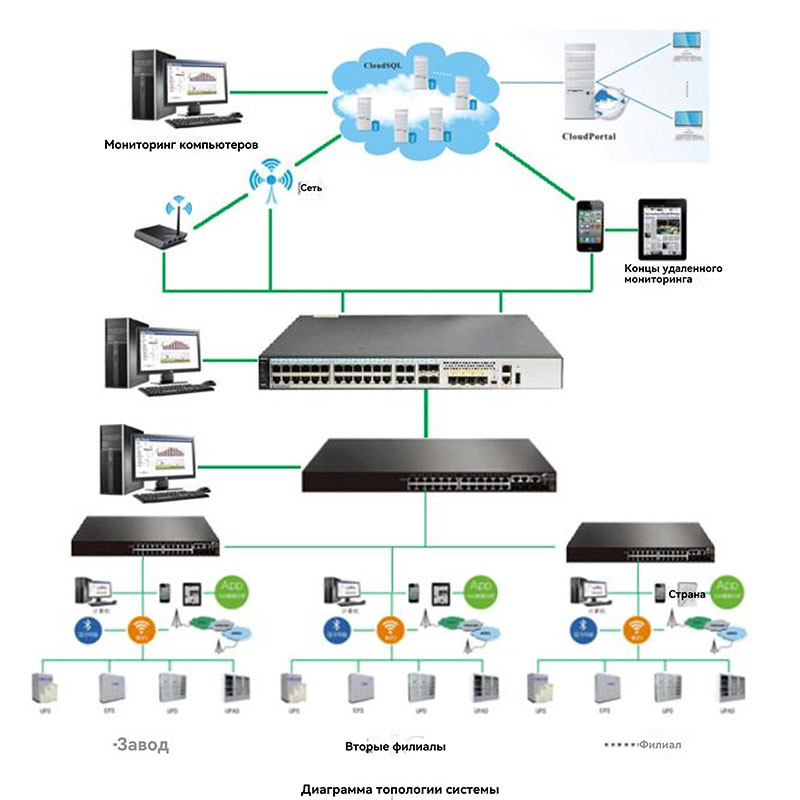 Система управления облачными сервисами комплексного мониторинга источник питания
Система управления облачными сервисами комплексного мониторинга источник питания -
 Промышленные и коммерческие системы хранения энергии RKCN
Промышленные и коммерческие системы хранения энергии RKCN -
 Промышленная литий-железо-фосфатная аккумуляторная батарея серии FEL
Промышленная литий-железо-фосфатная аккумуляторная батарея серии FEL -
 Биметаллический элемент температуры и влажности
Биметаллический элемент температуры и влажности -
 Специальный механизм манометра
Специальный механизм манометра -
 Волосковая пружина механического инструмента
Волосковая пружина механического инструмента -
 Гибридный шкаф электропитания EPS серии RK-D
Гибридный шкаф электропитания EPS серии RK-D -
 Сенсорный коммуникационный силовой шкаф UPD-Ⅲ тип
Сенсорный коммуникационный силовой шкаф UPD-Ⅲ тип -
 Промышленные ИБП серии HTM6000 (3-фазный вход/однофазный выход)
Промышленные ИБП серии HTM6000 (3-фазный вход/однофазный выход) -
 Источник питания постоянного тока серии UPDD
Источник питания постоянного тока серии UPDD
Связанный поиск
Связанный поиск- Поставщики резервных источников питания для центров обработки данных
- Обработка прямозубых цилиндрических шестерен
- Шкафы электропитания с возможностью удаленного мониторинга и поиска неисправностей
- Поставщик системы электропитания для железнодорожного транспорта
- Поставщик интегрированных энергетических решений для железнодорожного транспорта
- Поставщики коммерческих и промышленных систем электропитания с накопителями энергии для наружной установки все в одном
- Китайский производитель тепловых энергетических систем
- Онлайн ИБП
- Банки питания быстрого реагирования из Китая
- Поставщики шкафов питания постоянного тока в Китае



